
A Digital Humanities Solution: Browse, Search, Discover, Analyze – All in One
It has never been easier or more efficient to navigate adroitly the vast sea of collected Ancient Chinese textual knowledge collected in key Tang-, Song- and Qing-era leishu 類書 encyclopedic anthologies. The Han Cloud Research Platform offers state-of-the-art big data text mining tools to identify and analyze content and contextual connections between the various ancient texts contained therein. The platform's multidimensional search and visualization features foster readier discovery of unknown or unanticipated topics, issues and information through use of a few keywords, and offer unprecedented ease in bridging the differences in categorical schema between the leishu of these three major historical eras.
Database content
Full-text search and analysis of 7000 extracted or verbatim texts comprising 220 million graphs contained in the three most representative imperial government-compiled leishu encyclopedic anthologies—the Yiwen Leiju 《藝文類聚》, Taiping Yulan《太平御覽》, and Gujin Tushu Jicheng《古今圖書集成》.
Digital tools
- Macro-perspective categorical browsing
- Source and author search of compiled texts
- Full-text search and advanced affix / suffix analysis
- Graphic display of structural correspondences between different leishu
- Passage similarity analysis to bridge categorical differences
Interface preview

Leishu macro-perspective browsing
Displays the entire categorical structure of the selected leishu by tome (彙編), canon (典),and thematic section (部),showcasing the knowledge classification schema of the original printed form,and providing a coordinate schema for quickly zeroing in on a particular subject of study.

Passage Similarity Analysis
Similar content extracted or compiled in various categorical sections of a leishu or different leishu included in the Han Cloud database are automatically displayed together to highlight differences in concept classification,subject categorization and editorial logic among the encyclopedic anthologies.
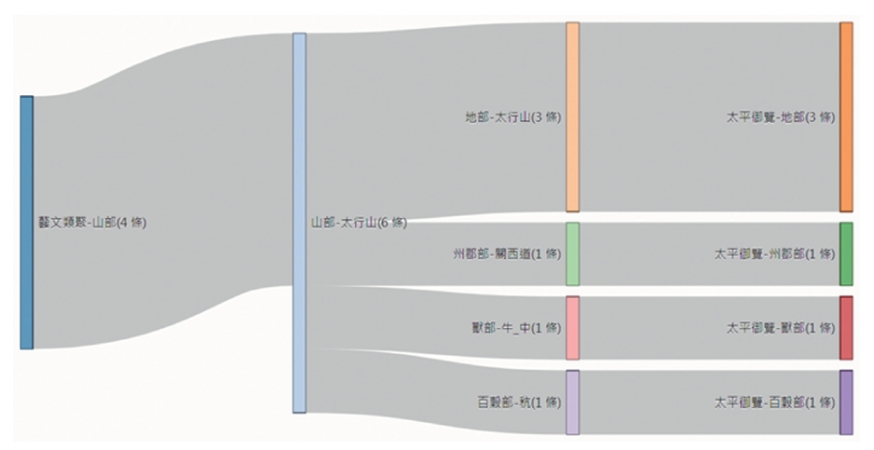
Graphic display of structural correspondences
Enhances clarity and readability of structural correspondences between leishu.
Analytical tools
- Text mining to parse and classify documents into structuralized data
- Text analysis of content and contextual connections between various passages
Macroscopic overview
- Categorical browsing to showcase ancient knowledge classification schema
- Graphic display of knowledge classification correspondences between leishu
Multidimensional search
- Conditional and original document structural classification search
- Advanced search feature provides full text, author, source and affix analysis
- Post-classification categories: source, author, era, cannon, and cannon-entry